AI HOUSE на зв’язку! Нам вже не терпиться поділитися з вами новинами та спершу — кілька крутих апдейтів від нас: Збираєтеся на DOU Day conference? Ми теж! Завітайте на наш спільний з Roosh Investment Group — AI Brunch. Будемо обговорювати останні апдейти AI-сфери, обмінюватися досвідом і нетворкати. Багато нетворкати. Адженда та деталі тут, а зареєструватися можна за посиланням.
- Раптом ви пропустили, то нагадаємо про останній епізод AI HOUSE Podcast з Миколою Максименко, Co-Founder & CTO Haiqu, членом борда AI HOUSE. Найбільше уваги у випуску приділили квантовим обчисленням. Обговорили те, як вони працюють та чим відрізняється квантове залізо від звичайного. Не забули й про квантові компʼютери, телепортацію та квантовий зв’язок. Дивіться на YouTube та слухайте на подкаст-платформах🔥
А тепер — до AI-новин! Розібратися з найгучнішими нам допоможе Ніка Сніжко, AI Automation Strategist та Prompt Designer. |
|
Британський єдиноріг Synthesia анонсував своїх нових AI-аватарів, які працюють на базі моделі EXPRESS-1 — і виглядають вони ну дуже реалістично. І це насправді значний прорив, адже раніше AI-аватари часто були далекими від ідеалу і страждали від скутості рухів, нереалістичних емоцій і інших глітчів. Synthesia, схоже, вдалось подолати ці недоліки — AI-аватари компанії точно відтворюють емоції та манеру спілкування людей, піднімаючи планку реалістичності технології на небачену висоту. Паростки AI-клонування вже зароджуються й у Голлівуді. Агентство Creative Artists Agency запустило пілот проєкту CAA Vault, що дозволяє селебам створювати свої цифрові копії. У партнерстві з AI-компаніями CAA створює повноцінні цифрові аватари клієнтів на основі їх тіла, обличчя та голосу. Такий «двійник» може допомогти акторам переозвучити себе в іншомовному дубляжі чи «приліпити» своє обличчя на дублера. Лінію між реальністю та згенерованим контентом планує стирати й TikTok. Дослідники покопалися в коді останнього оновлення застосунку для Android і знайшли там посилання на «Бібліотеку голосів TikTok», а також нову опцію «Створити свій голос за допомогою ШІ». Стверджується, що застосунку знадобиться лише 10 секунд, щоб згенерувати ваш цифровий голос, який потім можна буде використовувати для створення контенту <і бозна чого ще…>. Офіційної комунікації з цього приводу ще не було, тому пізніше побачимо, чи правдиві ці чутки. Цікавий кейс з використанням синтетичного голосу стався завдяки американському реперу Дрейку, який випустив дис-трек на Кендріка Ламара під назвою «Taylor Made Freestyle», у якому він використав згенеровані голоси реперів Тупака Шакура і Снуп Догга. Хайпанути вдалося, причому настільки, що згодом трек довелось видаляти через погрози судовим позовом від юристів Тупака. Проте якщо хочете його послухати — на Youtube повно копій <принаймні, поки що>, які завантажили фанати. Регулювання використання AI в креативних індустріях відстає від розвитку технологій на роки. Тому вчені з Deepmind закликають обмежити розробку AI-моделей, які імітують людей. Це стосується не лише AI-клонів чи згенерованих голосів, а й чат-ботів, які також майстерно імітують поведінку людей і спілкуються природною мовою. Дослідники стверджують, що потрібні серйозні дослідження взаємодії людини і AI та можливо навіть обмежити «олюднення» AI, щоб уникнути емоційної/матеріальної залежності від технології. |
|
Коментар Ніки: Якість дуже вражає. І це ще більше збільшує можливості для створення контенту у сфері маркетингу та інших креативних індустріях. Але досі невід’ємним і важливим питанням є політика використання та проблема вирізнення оригіналу від продукту згенерованого ШІ. Тому розробка стандартів і рішень з виявлення AI-контенту має бути настільки ж важливою, як і розробка нових продуктів та розвиток технології. |
|
2. Реліз і відгуки про Llama 3 |
|
Meta випустила дві нові моделі Llama 3 — на 8 і 70 млрд параметрів. Найбільша третя модель на 405 млрд параметрів вийде влітку, проте вже зараз Llama — найкраща оупенсорсна модель, що доступна на ринку. Через це велика кількість користувачів вже перейшли до роботи з Llama замість інших безкоштовних LLM-ок. В Meta кажуть, що продуктивність найбільшої моделі Llama 3 буде близькою до лідерів — GPT-4 Turbo, Claude 3 Opus тощо. Відкритим залишається питання, як компанія планує монетизувати свою розробку, адже на неї йде дуже багато ресурсів. Наприклад, бізнес-план Mistral полягає у тому, щоб користувачі експериментували з меншими моделями стартапу, після чого підписувалися на його найбільшу LLM, яка є платною. На додачу компанія працює над інтерфейсом прикладного програмування, який дозволить клієнтам файнтьюнити моделі самостійно і налаштовувати їх під себе. Звучить класно, проте насправді користувачі радісно користуються безкоштовними моделями, а гроші віддають за роботу з GPT-4 та Claude Opus, оскільки саме ці моделі є найкращими станом на зараз. Гіпотетично Meta може заробляти опосередковано, використовуючи AI-асистента на базі Llama 3, щоб користувачі більше сиділи в продуктах компанії Цукерберга. Крім того, AI-інновації можуть допомогти Meta зробити їхню систему рекомендацій ще кращою, збільшуючи доходи від реклами. Проте чи окупить це всі витрати — питання відкрите. |
|
Коментар Ніки: Llama 3 дійсно показує дуже хороші результати. Припускаю, що наразі вони, працюючи безплатно, збирають дані про звички користувачів, щоб покращити модель, щоб вже потім почати монетизувати, маючи найкращу якість серед конкурентів. Якщо результати Llama будуть кращими за GPT, Claude та інші моделі, а ціна буде прийнятною — я впевнена, що буде багато компаній, які будуть готові платити Meta за якість. Адже досить часто бізнеси використовують різні моделі залежно від конкретної задачі та мови. Проте зараз Meta не потребує генерації доходів від мовних моделей і може не поспішати з монетизацією, адже самі активно використовують їх у своїх продуктах. Це дозволяє їм вдосконалювати залучення користувачів, оптимізовувати рекламу та надавати преміальні послуги з аналітики, генерації інсайтів тощо. |
|
Тепер будь-який смартфон чи ноутбук може мати власного AI-асистента. Microsoft зарелізив ряд компактних мовних моделей Phi-3, серед яких Phi-3 mini. Це компактна та водночас потужна LLM на 3,8 млрд параметрів, спроєктована так, щоб точно імітувати можливості в 10 разів більших моделей, що робить її конкурентоспроможною з більшими моделями ШІ. Попри свій розмір, вона показує результати на рівні Mixtral 8x7B і GPT-3.5, досягаючи 69% в бенчмарку MMLU і 8.38 в MT-bench. Крім mini невдовзі будуть доступними також моделі Phi-3 small на 7 млрд параметрів і Phi-3-medium на 14 млрд <вони все ще тренуються>, які переважать mini за тими самими бенчмарками. Для навчання моделі Microsoft створила унікальну базу даних для навчання. Компанія використала розширену версію датасету від Phi-2, де поєднали відфільтровані дані з інтернету і синтетичні дані. Досвід Microsoft демонструє, що правильні методи навчання і якісний датасет дозволяють навіть маленьким LLM демонструвати неабиякі результати. |
|
Коментар Ніки: Phi-3 Mini є значним прогресом для галузі, демонструючи, що менші моделі так само можуть забезпечувати високу продуктивність. Основними обмеженнями моделі, порівняно з іншими LLMs, є обмежена здатність зберігати обширні фактичні знання, та можливість працювати з багатьма мовами (Phi-3 сфокусована на обробці англійської мови). Попри ці недоліки робота моделі заслуговує на похвалу. Здатність працювати локально на телефоні, без необхідності підключення до інтернету відкриває нові можливості для мобільних застосунків. Такий рівень якості в такому малому розмірі є переломним моментом для GenAI-програм. І думаю що це початок активного розвитку менших мовних моделей та мовних моделей орієнтованих на спеціалізовані галузі. |
|
✈️Повітряні сили США розказали про перше успішне випробування повністю автономного AI-пілота в повітряному бою. У вересні 2023 року керований AI експериментальний літак X-62A провів навчальний повітряний бій проти F-16 під керуванням людини. Хто переміг, американці не розповідають, проте кажуть, що все пройшло добре. 💣Microsoft запропонувала Пентагону використовувати ChatGPT і DALL-E для розробки ПЗ військового призначення. ChatGPT міг би допомогти військовим аналізувати документи та обслуговувати техніку, а DALL-E — створювати синтетичні дані для навчання систем управління боєм, що дозволило б комп'ютерам Пентагону краще «бачити» умови на полі бою. 🤖МЗС України запустило AI-аватар Вікторію для озвучення офіційних заяв. Під час резонансних подій за кордоном, міністерство отримує велику кількість запитів; щоб розвантажити речника, в МЗС вирішили створити AI-аватара. Щоб запобігти розповсюдженню фейків, усі відео з Вікторією будуть промарковані QR-кодами із посиланнями на офіційну сторінку МЗС України із відповідними заявами. ❄️Snowflake представила свою відкриту мовну модель Arctic <Github — тут, HuggingFace — тут>, яка, за словами компанії, перевершує Llama 3 від Meta за деякими метриками, водночас витрачаючи вдвічі менше обчислювальних ресурсів на навчання. Arctic поєднує традиційну трансформерну модель і mixture of experts — Snowflake називає свій варіант «Dense - MoE Hybrid Transformer». Подібний підхід нещодавно використали Databricks у своїй моделі DBRX та стартап AI21 Labs у Jamba, про які ми розказували у нещодавньому дайджесті. 🐲Китай продовжує нарощувати потужності у сфері AI — два нових релізи потенційно можуть скласти серйозну конкуренцію OpenAI і ко: - Компанія SenseTime випустила SenseNova 5.0 — мовну модель на ~600 млрд параметрів з контекстним вікном у 200 тис. токенів, яка перевершила GPT-4 Turbo за деякими бенчмарками. Модель тренували на понад 10 ТБ переважно синтетичних даних і вона демонструє значні покращення у сферах математики, логіки та написання коду.
- Тим часом компанія ShengShu представила Vidu, генератор відео з тексту, який нібито не поступається непредставленій Sora від OpenAI. Vidu вміє генерувати 16-секундні відео у роздільній здатності 1080p, точно передаючи освітлення, тіні та емоції. Модель вже продемонстрували на прикладах з пандою-гітаристом та цуценям, що плаває 🎥
🖼Adobe додала нові інструменти генеративного AI у Photoshop. З найцікавішого — тепер можна давати програмі власне зображення, яке виступатиме референсом для наступних генерацій картинок; змінювати та генерувати фон з нуля та апскейлити зображення. 🔓На чат-бот арені з’явилася <і вже зникла> загадкова gpt2-chatbot, яка загалом працює на рівні з GPT-4 та Claude Opus, а деякі завдання розв’язує краще за них. Користувачі активно спекулюють, що це — стелс-тест майбутньої GPT 4.5 або наступної ітерації GPT4, проте поки що ніяких деталей нема; є лише загадковий твіт Сема Альтмана, про те, що йому «дуже подобається gpt2». 🍏Apple представила набір з чотирьох мовних моделей OpenELM <270 млн, 450 млн, 1,1 млрд і 3 млрд параметрів, лінки на HuggingFace і GitHub>, які завдяки своїм невеликим розмірам можуть працювати локально на пристроях без доступу до хмарних сервісів. Контекстне вікно моделей невелике — всього 2048 токенів — проте це точно не є головною кіллерфічею цих моделей. Паралельно компанія веде переговори з OpenAI для підтримки AI-функцій в Айфонах та Маках; проте в Apple ще не визначились з партнером <паралельно тривають переговори з Google>. 🧩Ще одна радість для власників Айфонів — Anthropic випустив застосунок Claude для iOS. Все як треба — зручно, швидко, гарно, можна завантажувати фотки для роботи з ними. Реліз на Android планується найближчим часом. 🎨З’явився аналог арени чат-ботів <де користувачі всліпу обирають найкращу на їхню думку відповідь різних LLM з двох обраних>, але для моделей, які генерують зображення. Топ-3 станом на сьогодні — Modjourney, Stable Diffusion, Dalle 3. 🧠OpenAI розгортає функцію пам’яті ChatGPT для ще більшої кількості безплатних та платних користувачів. Завдяки цьому чат-бот зможе переносити отримані знання з однієї розмови в іншу — ви буквально можете попросити GPT запам’ятати або «забути» якийсь факт, які потім можна переглянути у вкладці персоналізації. 📝Також OpenAI уклала угоду з Financial Times — відтепер ChatGPT зможе включати посилання на статті FT у своїх відповідях. Паралельно на OpenAI та Microsoft подали в суд ще ряд медіа, що належать Alden Capital Group; звинувачення такі самі, що й у випадку з NYT — використання матеріалів видань без їхньої згоди для тренування GPT. Ще одна нова угода OpenAI — з Moderna; біотехнологічний гігант інтегрує ChatGPT у всі свої бізнес-процеси для прискорення розробки ліків. В компанії вже створили понад 750 персональних GPTs + відбувається близько 120 розмов з ChatGPT на одного користувача за тиждень. 🧬Стартап Profluent розробив OpenCRISPR-1 — ця розробка здатна редагувати геном людини та працює на базі AI. Потенційно це важливий майлстоун, оскільки редагування генів має величезний потенціал для медичної галузі; вчені сподіваються, що штучний інтелект виведе цю технологію на новий рівень. OpenCRISPR-1 має відкритий код, щоб інші дослідники могли тестувати технологію. 📹Сценарист і режисер Пол Трілло випустив перший кліп, повністю згенерований за допомогою Sora від OpenAI. Чотирихвилинний кліп для музиканта Washed Out складається з 55 відео, змонтованих у нескінченний рухомий кадр. |
|
Китай випереджає США за одним із ключових показників у сфері AI — таланти США поки що є лідерами у розробці чат-ботів, якими користуються люди з усього світу. Водночас Китай працює на перспективу, і, як виявилось, вже обганяє Америку за кількістю топових AI-дослідників. Згідно з новим дослідженням аналітичного центру MacroPolo, майже половина провідних світових фахівців зі штучного інтелекту — випускники китайських вишів <ще три роки тому цей показник становив близько 30%>. Для порівняння, лише 18% талантів приходять з американських університетів — за цей час ця частка майже не змінилася. Цей дисбаланс накопичується вже майже 10 років. Протягом більшої частини 2010-х багато китайських спеціалістів їхали в США, щоб здобути докторський ступінь і залишитись там працювати. Зараз ця тенденція змінюється — все більше китайців воліють залишатися на батьківщині. Найближчі кілька років можуть стати визначальними, адже Китай і США змагаються за першість у сфері штучного інтелекту. Тому AI-дослідники поступово стають однією з найважливіших геополітичних груп у світі. Попри те, що AI-бум очолюють американські компанії на кшталт OpenAI та Google, Китай активно вкладається в AI-освіту — так, з 2018 року в країні з’явилися понад 2000 нових програм, пов’язаних зі штучним інтелектом, що дає Китаю значну фору в перспективі. Хоча США є країною-лідеркою в AI станом на зараз, значну частину успіху Америці принесли дослідники з Китаю — 38% у порівнянні з 37% дослідниками-американцями. Ще три роки тому це співвідношення було 27% проти 31% на користь США. І якщо раніше американські урядовці не надто переймалися цим, зараз ситуація змінюється. Нещодавно китайського інженера Google звинуватили у спробі передати чутливі AI-розробки пекінській компанії. Подібні кейси ставлять політиків перед складним вибором: з одного боку, треба протидіяти китайським шпигунам, з іншого — не відлякувати талановитих інженерів з Китаю. Поки що більшість китайців, які здобувають докторські ступені в США, залишаються в країні. Але лідерство США починає слабшати — зараз у країні працюють близько 42% найкращих світових талантів, порівняно з 59% три роки тому. Що буде далі в цих перегонах за AI-спеціалістів — велике питання. Але одне зрозуміло точно: від того, хто переможе, багато в чому залежатиме, хто домінуватиме в наступній технологічній революції. |
|
Що робити з проблемою Lost in the middle? |
|
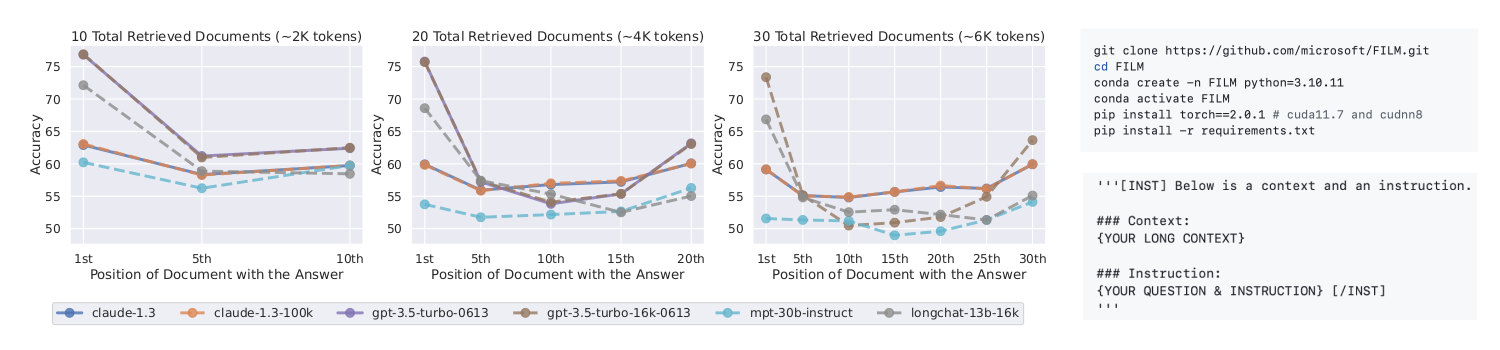
Ви, напевне, знаєте про одну з головних проблем сучасних LLM, які працюють з великою кількістю вхідних даних: вони чудово запам’ятовують початок і кінець довгого тексту, але часто гублять те, що знаходиться посередині. Така «забудькуватість» робить LLM ненадійними при обробці великих обсягів інформації попри їхню здатність працювати з довгим контекстом. Команда дослідників з Microsoft, Пекінського університету та Університету Сіань Цзяотун вважає, що причина криється у методах навчання LLM. Під час навчання на великих масивах даних, моделі вчаться передбачати наступне слово на основі попередніх. Вже під час файнтьюнінгу моделей дослідники зазвичай розміщують інструкції на початку промпту — це формує у LLM «упередження», що важлива інформація завжди знаходиться на початку або в кінці тексту. Щоб допомогти моделі не втрачати весь контекст, вчені пропонують новий підхід — IN2 <INformation-INtensive training, інформаційно-інтенсивне навчання>. Головна ідея — показати моделі, що важливою є абсолютно вся інформація з промпту. Для цього використовується синтетичний датасет запитань-відповідей. Замість цілісних текстів, дослідники «нарізають» довгі документи (4-32 тис. токенів) на короткі сегменти (по 128 токенів) і довільно «перемішують» їх. Потім вони генерують запитання, відповіді на які потребують інформації саме з цих сегментів, причому незалежно від їхньої позиції в контексті. Запитання бувають двох типів: 1. Ті, що вимагають точної інформації лише з одного сегмента; 2. Ті, що потребують поєднання та логічного виведення інформації з кількох сегментів одночасно. Ці запитання і відповіді на них генеруються за допомогою потужної мовної моделі (в дослідженні - GPT-4 Turbo). А різноманітність запитань та довільне «розкидання» сегментів по контексту привчають модель уважно вивчати весь текст незалежно від його розташування. Ефективність методу IN2 дослідники перевірили на моделі Mistral-7B, зробивши на її базі модель FILM-7B <ловіть лінку на GitHub>, яку протестували на трьох завданнях, що вимагають вилучення інформації з довгих контекстів — аналіз документа, коду, структуризація даних. Виявилось, що FILM-7B має значно кращу «пам’ять» на довгих контекстах порівняно з оригінальною Mistral-7B. Ба більше, попри менший розмір <7 млрд проти 175 млрд> FILM-7B показала результати на рівні або навіть краще, ніж GPT-4 у деяких long-context завданнях. Водночас FILM-7B зберегла високу якість і при роботі з короткими текстами. Цікаво, що популярний тест «Голка в копиці сіна» <Needle-in-the-Haystack> виявився не надто показовим для оцінки справжніх можливостей моделей працювати з довгим контекстом, адже він спирається на звичні для LLM документоподібні тексти і прямий пошук інформації. Натомість вони пропонують свій підхід VAL Probing, який охоплює різні стилі контексту <документи, код, структуровані дані>, завдяки чому нібито дає більш об’єктивні результати. Дослідники стверджують, що IN2 не є чарівною пігулкою від «амнезії» LLM. Проте їхній підхід доводить: щоб навчити AI по-справжньому розуміти людей, інколи варто дати йому завдання, з якими стикаємось і самі. Наприклад, знайти потрібну інформацію в довгому, складному, «перемішаному» тексті. Щось знайоме, чи не так? |
|
|
|---|
|
Дякуємо, що дочитали! Не забудьте порадити наш дайджест своїм знайомим, яким цікава тема AI/ML. А усі побажання, питання та поради для покращення ньюзлеттеру можна традиційно залишити за посиланням 🙂 |
|
|
|---|
|
AI HOUSE — найбільше та найпотужніше АІ-комʼюніті в Україні. Обмінюємось досвідом і знаннями, здобуваємо навички, реалізовуємо нові технологічні та бізнесові ідеї, розвиваємо індустрію та сприяємо народженню продуктових AI-стартапів. AI HOUSE є частиною екосистеми технологічної компанії Roosh. |
|
|
|---|
|
|
|